REGULAR EXPRESSIONS with Python a beginners guide — Part 2
Building blocks of regex with examples in re.
The building blocks of regex includes Characters and Character Classes, Quantifiers, Logic, Anchors and Boundaries, and Look arounds. In the following topics we will discuss each building bocks with easy examples that you can follow. Let us see how to build regexes with these building blocks.
Characters and Character Classes
Characters or literals are the most basic building blocks of regex. For example, r’regex’ matches word ‘regex’ in a sentence.
There are also character classes that are used to define a set of allowed characters. These set of allowed characters are written between square brackets, and each allowed character is listed eg: “[aeiou]” or we can provide consecutive characters as ranges using the dash operator eg: [0–9]
If a character class definition begins with a ‘^’, the set of listed characters is inverted.
Regex provides the following patterns to match characters. We will build patterns with these.
- \w matches word characters, while W matches non-word characters
- \d matches digits, while D matches non-digit characters
- \s matches whitespace characters, while S matches non-whitespace characters
- . (dot) matches any letter or symbol (wildcard)
- [x-y] One of the characters in the range from x to y, The bracket [] matches characters in it
- [^x] One character that is not x
Example 5

Here 2 ‘\w’ which follows ‘reg’ matches any 2 word characters. Since we are using ‘re.findall()’, all the substrings with ‘reg’ followed by 2 word characters are returned here. So the output is a list — [‘regul’, ‘regex’]
Example-6

Above is another example similar to the previous example. Here we see 4 ‘\w’ characters after ‘reg’ which matches 4 word characters following ‘reg’.
Example-7

In the above example we use ‘\W’ instead of the \w hence word characters are ignored and match is made to non word characters. For example in the example above ‘regular’ is ignored whereas the match is found at ‘reg#’. Also only one \W is provided hence it will match only one non word character after ‘reg’.
Example-8

Suppose that we want to match numbers in a string and not alphabets. We can do this in regular expression using the special character ‘\d’. In the example above we can see that single digits are found as match.
Example-9

Just as ‘\W’ inverted the results for \w using \D inverts the results for \d. The results are opposite to that of \d i.e. the match is made to any non digit characters. The ‘\D\D\D’ matches any three consecutive non digit characters.
Example-10

We have seen regex syntaxes to find word characters and digits. Similarly in regular expression, syntax for finding space characters is ‘\s’. The \s matches all space characters in the string. We can see that, in the example above all the three spaces from the string is found.
Example-11

In the example above the capitalized \S matches all characters except space characters. So the output is as shown above. All symbols ignoring all the space characters are returned.
Example-12
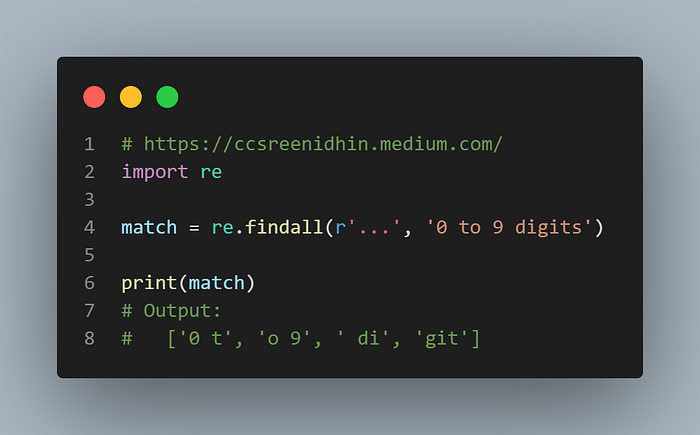
The ‘.’ is another special character in regular expression which matches all characters except newline characters. In the example above the three dots ‘…’ matches against any three characters in the string. But be careful that ‘.’ ignores newline characters.
Example-13
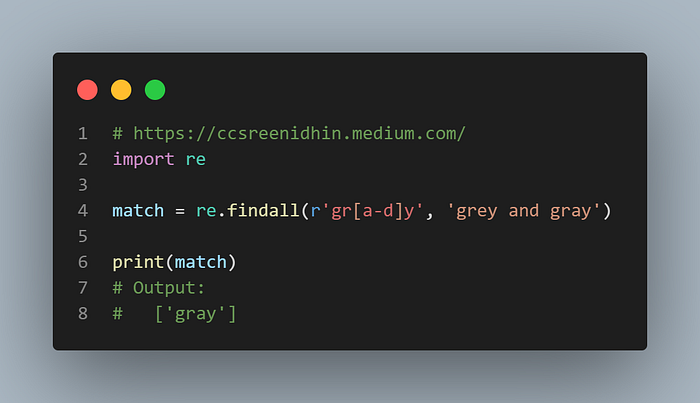
Character classes or character sets are used to match a character from a set of characters. In here regex will match against any character between a-d after ‘gr’ which is followed by y. So here only ‘a’ falls in the range from [a-d], hence only gray is matched. Note that hyphen ‘-’ between characters matches a range of characters on either end of ‘-’ based on ASCII table values. So [!-~] is also a valid range. Also we can provide multiple ranges inside the square brackets. The order of characters or ranges does not matter. Only one out of the several characters is matched.
Example-14

If we want to match any one character from ‘a-z’ after ‘gr’ we can write as shown above. The pattern not only matches grey or gray. But it will match any alphabet. Note that to match capital letters we can provide range as [A-Z].
Example-15
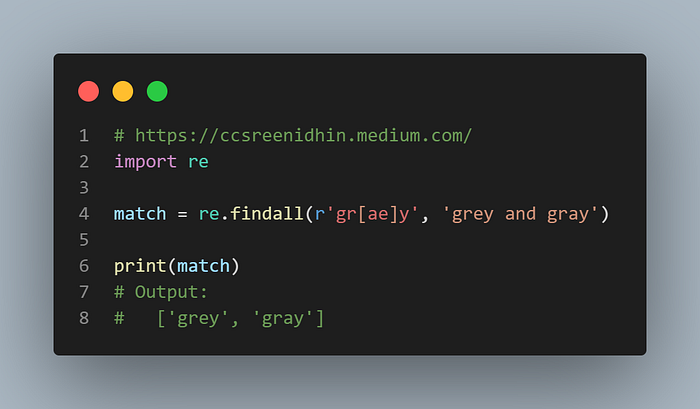
Let us suppose we are given a data set with grey spelled as grey and gray. We need to match both the spellings. We can use character classes to achieve this as shown above. Here the ‘re.findall’ matches both ‘grey’ and ‘gray’ whereas characters other than ‘a’ or ‘e’ are ignored.
Example-16
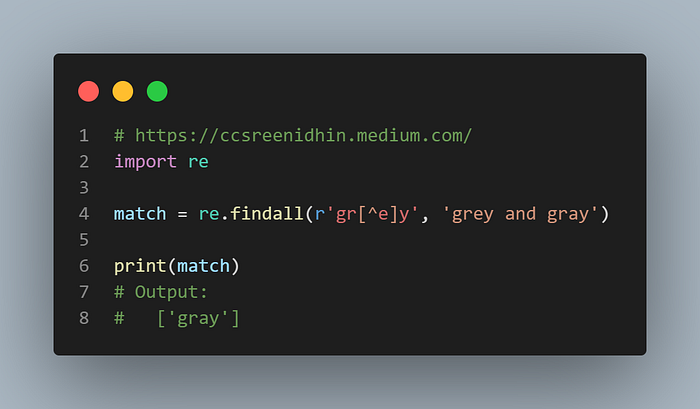
Now suppose in the previous example, the word grey was not to be matched whereas any other character is alright to match, how will we do it ?. In this case we can use ‘^’ this is equivalent to saying that “match a character that is not e” or “match a character that is not the same as the one that follows’ ‘. So in the example above all characters except ‘e’ will be matched.
Special Characters
We have discussed some of the characters with special meanings above. Below is a list of special characters used in regular expressions. There are 11 characters with special meanings also called metacharacters. These must be escaped with ‘\’ to match simply as character:
Quantifiers
Quantifiers help specify the expected number of matches of a pattern. For example ‘colou?r’ matches 0 or more ‘u’ after ‘o’ such that both ‘color’ and ‘colour’ is a match. In our previous examples we have not used any quantifiers. Any single character matched a single character in the string. In the coming topics we will use quantifiers to quantify the no of matches to be made.
- + matches one or more of the preceding
- {x} matches exactly x(number)
- {x, y} matches x(number) to y(number) of times
- {x,} matches x(number) or more times
- * matches 0 or more times
- ? matches once or more times(lazy)
Example-17
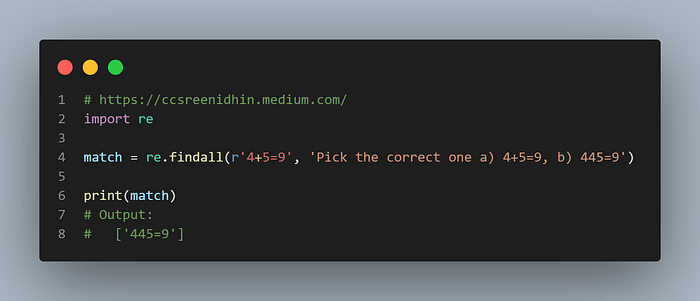
Here the pattern ‘4+5=9’ matches ‘445=9’ because the ‘+’ symbol has a special meaning in regular expressions. The ‘+’ symbol is a quantifier, it matches ‘1’ or more occurrences of the preceding character. So in the string ‘4+5=9’ is ignored whereas ‘445=9’ is matched. The same will match any number of 4’s but at least one followed by ‘5=9’.
Example-18
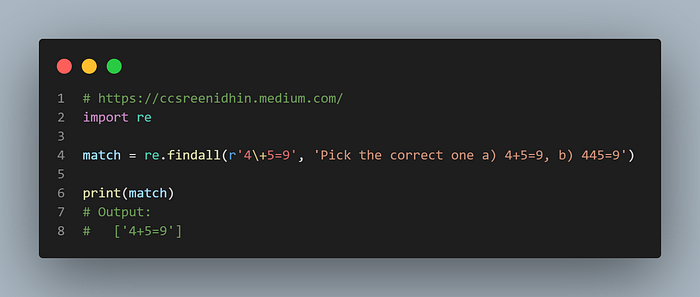
In order to match ‘4+5=9’ itself and not any series of 4 followed by ‘5=9’ we have to escape the ‘+’ symbol with ‘\’ as in the example above. And the output is ‘4+5=9’.
Example-19
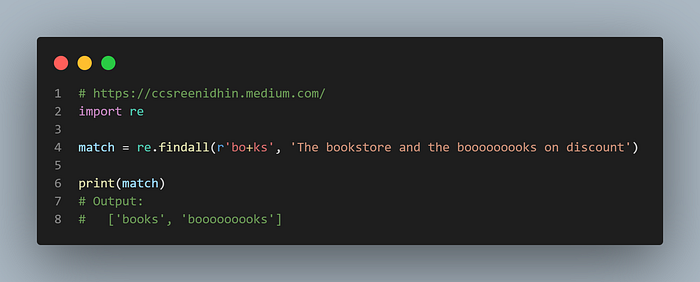
Notice that in the example above we ‘o’ followed by the ‘+’ symbol will match any no of o’s (1 or more). So “books” as well as “boooooooks” are matched.
Example-20
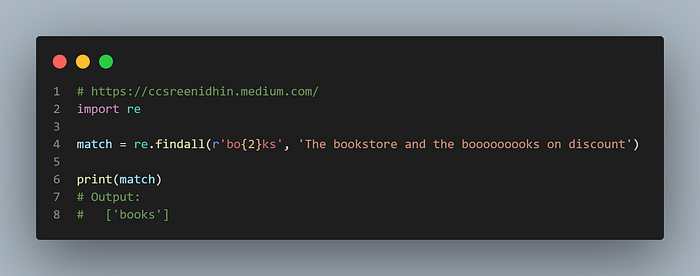
Sometimes we require a specific number of characters to match. For example we need to match the correct spelling of book ‘b’ followed by 2 o’s. In such cases we can use the ‘{number}’ quantifier to match a specific number of preceding characters. Here in the example only books are matched and any number of o’ s other than 2 is ignored.
Example-21
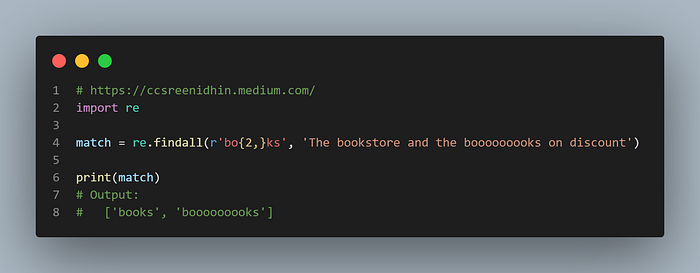
Let our match criterion be such that we match at least 2 o’s and more than 2 is okay. Then we can write as given in the above example. Here all spellings with at least minimum of 2 o’s are matched.
Example-22
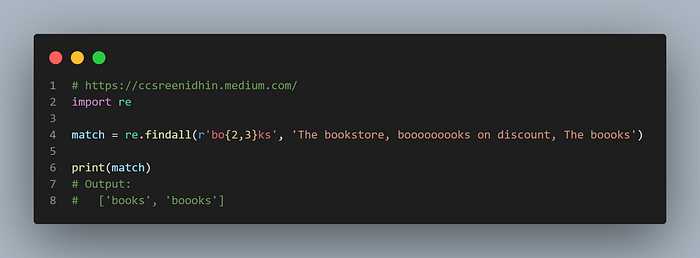
We can even specify a range of values to match. In the example above the no of o’s should be between two and three. So both “books” and “boooks” are correct whereas “boks” and “booooks” will be ignored.
Example-23
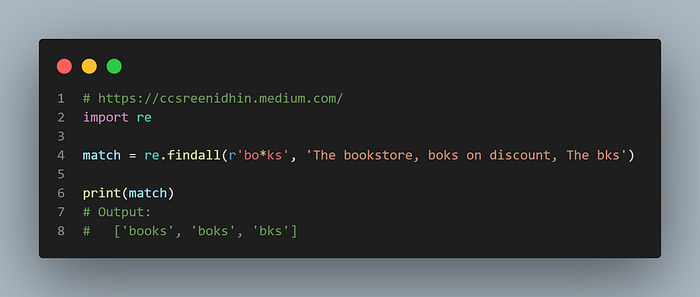
The ‘*’ is another special symbol in regular expression. It matches 0 or more of the preceding characters. For example, in the above code the ‘findall’ matches “books”, “boks” or even “bks”. As o is followed by * here mean 0 or more o’s. Note that + symbol matched 1 or more in the previous example, but here it is 0 or more.
Example-24
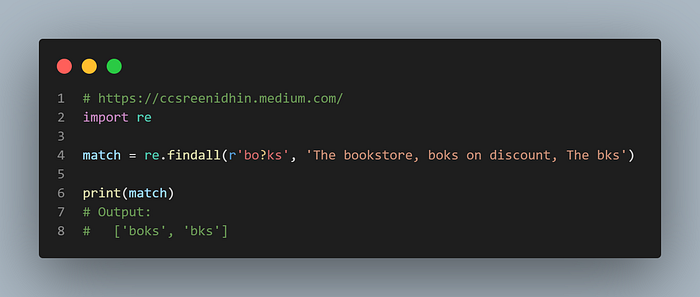
The ? Symbol makes lazy matches, whereas in the previous examples the * and + were greedily matching any no of characters. The ? matches 0 or 1 of times the previous character. It tries to match the minimum number of characters. Now combination of ‘*’ and ‘?’ i.e. ‘*?’ will make as few matches as possible. Also the same goes with the ‘+’ followed by ‘?’. For example the pattern ‘bo*?’ will match b 2 times in a string ‘The boookstore at NY books’. We can see that o is not matched at all.
Logic
In order to support more complex search algorithms we use the logical syntaxes in regular expressions. We will discuss grouping, conditionally matching(or), back referencing and grouping without capturing in the following topics.
- | or operand
- () defines a capturing group
- \1 backreference group 1
- (?: …) Non- capturing group
Example-25

The ‘|’ in regular expression works similar to an or operator in programming. Here the pattern implies to match either Cat or a Dog in a string. A string with Cat or Dog as substring will be matched here.
Example-26
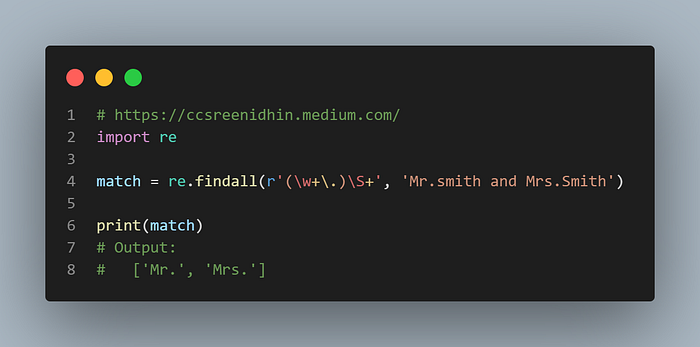
Sometimes we require to group out matches rather than just matching. We can group matches in a regular expression by putting the expression inside brackets (). The substrings matching the pattern within the two brackets will be grouped. Here word characters followed by ‘.’ are captured as a group.
Example-27
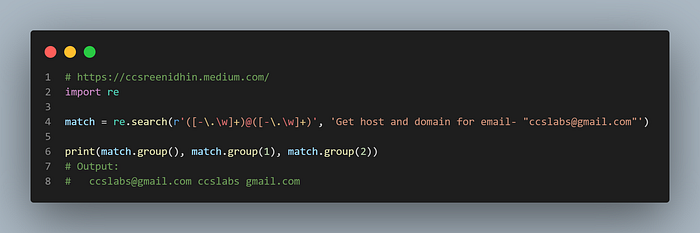
In the above expression we are matching emails. Here the first group ‘([-\.\w]+)’ matches the username and the second group following the ‘@’ character matches the domain. One or more hyphens, dots or word characters are allowed in both username and domain. The group 1 gives the user name and the group 2 the domain here. Also the ‘group()’ gives the complete match
Example-28
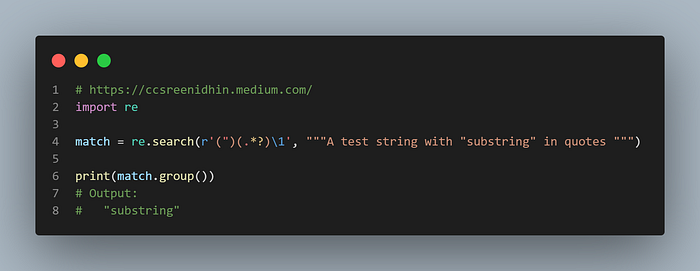
Backreferencing regular expression groups is used to match previously found string patterns. Suppose that we need to get a substring between a pattern repeated later. We can group patterns in regex and use backreferencing to match the group object. In the above example the quotation marks between brackets make the 1st group. Followed by 0 or more characters lazily matched (.*? — for matching lazily). Instead of repeating the 1st group again, we use \1 here which implies to match the substring matched by the pattern in the 1st group.
Example-29

We may want to find consecutive repetitions of words in a string which happens while typing, for example typing ‘the’ two times in a string etc. In such cases too the backreferences can become handy. Here ‘\b’ stands for word boundary that is the beginning or end of a word (discussed under anchors and word boundary). Here (\w+) matches word characters which are preceded by word boundary characters and followed by one or more space characters and followed by the same word characters(using \1) and a word boundary character again.
Example-30

(?:pattern) makes the group non-capturing, i.e. the pattern is not captured as a group. So here the double quotes are ignored from capturing.
Anchors and Boundaries
Anchors or Boundary matchers do not match a character as such, they match a boundary. They match the positions between characters. For example — a word boundary, in most regex dialects, is a position between \w and \W (non-word char), or at the beginning or end of a string if it begins or ends (respectively) with a word character ([0–9A-Za-z_]). Also ‘^’ matches at the start of the line. And ‘$’ at the end of a line.
- ^ Start of string or start of line
- $ end of string or end of line
- \b word boundary
Example-31

‘^’ at the beginning of the pattern matches the pattern at the beginning of a string i.e. match is successful if string starts with ‘The’. In the example above also note that the pattern does not match beyond ‘\n’ as ‘.’ ignores newline characters.
Exampl-32
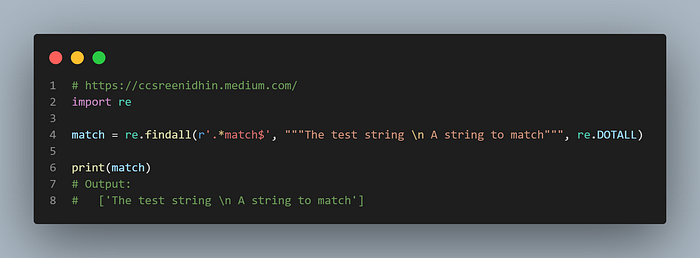
We can match at the end of the string too. For this the pattern should end with ‘$’. ‘$’ sign matches at the end of a string. The string with ‘match’ at the end will be matched here. Note that we are using ‘re’ flag ‘re.DOTALL’ in the above example.
Example-33
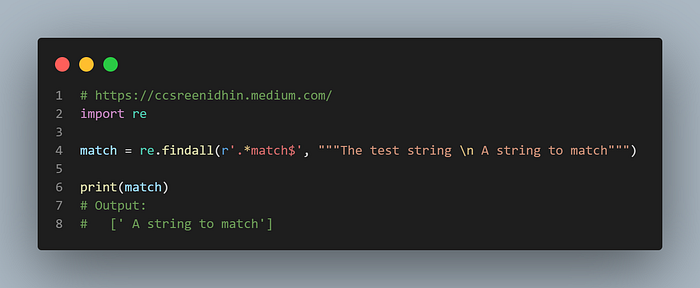
When the re.DOTALL is not used the pattern matches only the 2nd line (characters after the newline) flag hence the complete string is not matched as ‘.’ ignores ‘\n’ character.
Example-34
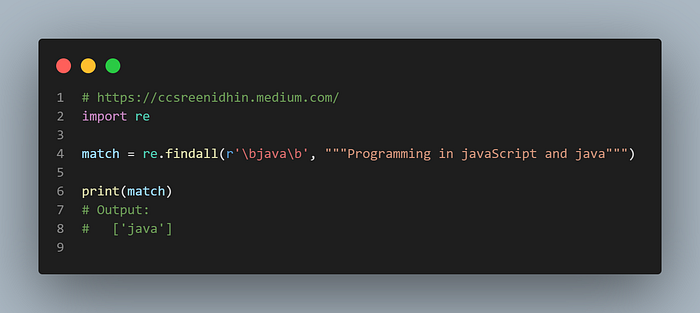
We have seen \b in one of the previous examples. Above is an easier example. In the example above ‘javaScript’ is not matched as java is followed by non boundary characters in ‘javaScript’.
Lookarounds
Sometimes we need to find only those matches for a pattern that are followed or preceded by another pattern. There’s a special syntax for that, called “lookahead” and “lookbehind”, together referred to as “lookaround”.
X(?=Y) — Positive lookahead X, if followed by Y
X(?!Y) — Negative lookahead X, if not followed by Y
(?<=Y)X — Positive lookbehind X, if after Y
(?<!Y)X — Negative lookbehind X, if not after Y
So the regex usage for the lookahead and look behind is as follows:
- (?=…) positive lookahead
- (?<=…) positive lookbehind
- (?!…) Negative lookahead
- (?<!…) Negative lookbehind
Example-35
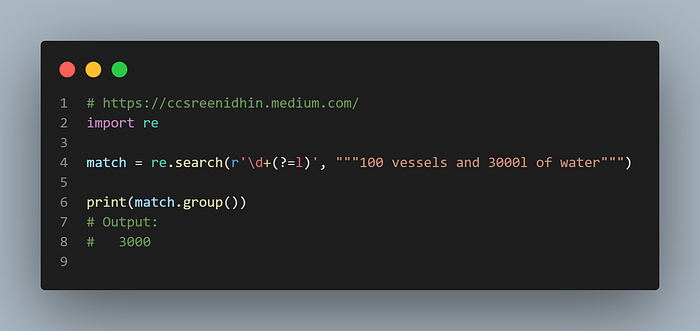
Above is an example of a positive lookahead. The substring with 1 or more digits followed by ‘l’ is matched. So the output is 3000.
Example-36
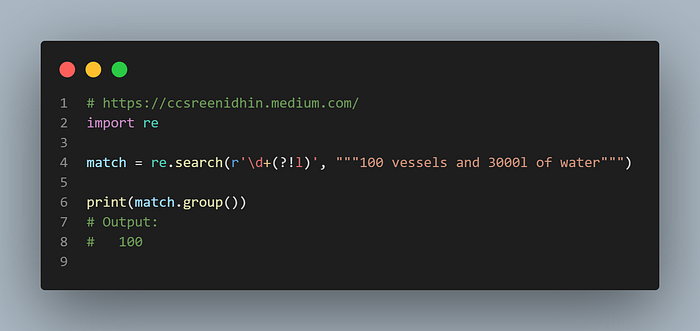
An example of a negative look ahead is given above. Here 1 or more digits that are not followed by letter ‘l’ are matched.
Example-37
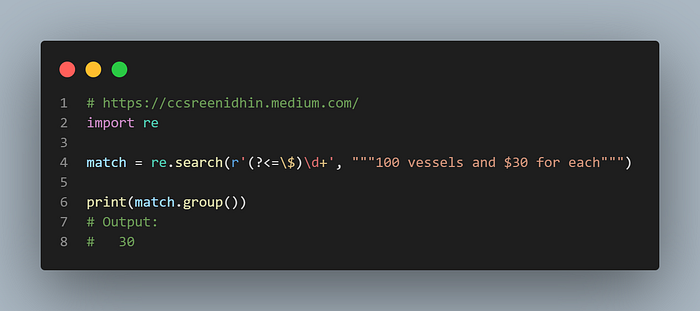
In the example above positive look behind is used. Here the digits with $ at the beginning are matched.
Example-38
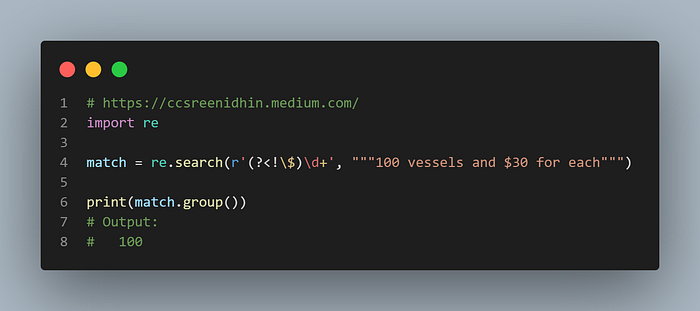
Negative look behind searches a substring which is not preceded by the pattern. In the example above the pattern looks for one or more digits not followed by ‘$’ sign.
A few pattern examples to practice:
Now try to evaluate the following patterns by yourself first..
- ’^(?=\S{6,20}$)(?=.*?\d)(?=.*?[a-z])(?=.*?[A-Z])(?=.*?[^A-Za-z\s0–9])’
Let us analyze the above pattern. Here ‘^’ indicates starting with, followed by a positive lookahead pattern — (?=\S{6,20}$). The ?=\S{6,20}$ matches 6–20 non space characters. So it looks ahead for 6–20 non space characters. (?=.*?\d) looks ahead for a digit which follows 0 or more characters. (?=.*?[a-z]) looks ahead for a lowercase alphabet. (?=.*?[A-Z]) looks ahead for an upper case alphabet. (?=.*?[^A-Za-z\s0–9]) looks for a character that is not an alphabet or, digit or space character.
The above is an example of a password validator. It checks for password length 6–20, presence of a digit, small letter and capital letter alphabets and any special characters.
2. ’^\w+([.-]?\w+)*@\w+([.-]?\w+)*(\.\w{2,3})+$’
The above pattern looks for a string starting with word characters (1 or more) followed by an optional group — ‘.’ or ‘-’ followed by 1 or more word characters. Then the ‘@’ symbol is followed by 1 or more word characters which is followed by an optional group of word characters starting with ‘.’ or ‘-’, this in turn is followed by one or more groups with ‘.’ and 2 to 3 word characters to the end of the string.
So as you can see, this is an example of an email validator.
Read from the beginning of the story. Go to Beginners guide to REGULAR EXPRESSIONS with Python — Part 1
